
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Activation Function
- Brightics EDA
- 삼성 SDS
- paper review
- pymysql
- michigan university deep learning for computer vision
- 브라이틱스 분석
- 분석 툴
- 범주형 변수 처리
- 파이썬 내장 그래프
- Brightics AI
- 브라이틱스 프로젝트
- Deep Learning for Computer Vision
- 머신러닝
- 비전공자를 위한 데이터 분석
- 브라이틱스 서포터즈
- 삼성 SDS 서포터즈
- 데이터 분석 플랫폼
- 브라이틱스 AI
- Random Forest
- 브라이틱스 스태킹
- Python
- 딥러닝
- Brigthics Studio
- 서포터즈 촬영
- Brightics studio
- 파이썬 SQL 연동
- 검증 평가 지표
- Brightics 서포터즈
- 데이터 분석
- Today
- Total
하마가 분석하마
[분석 실습-2주차] Brightics Studio 미니 프로젝트 본문
안녕하세요.
Brightics 서포터즈 노승찬입니다.
3주 동안 미니 프로젝트를 진행한다고 말씀드렸는데요. 2주 차는 이진 범주를 가진 변수들을 더 살펴보고, 연속형 변수들의 이상치 여부를 파악해 보겠습니다. 마지막으로 feature engineering을 진행하며 포스팅을 마무리해보려 합니다!
Brightics Studio를 활용한 미니 프로젝트 2주 차입니다.
프로젝트의 목표가 무엇인지 다시 한번 되새겨 보죠. 이번 미니 프로젝트의 목적은 은행의 제품에 대한 고객의 구매 여부를 예측하는 분류 모델을 구축하는 것입니다. 먼저 범주형 변수를 마저 보도록 하겠습니다.
1. EDA 2

통계량에서 확인했던 중요한 변수들의 그래프입니다. duration 변수에서 0과 1이 그나마 구분되는 것이 보입니다. 3개의 변수 모두 이상치가 많이 존재함을 알 수 있습니다.
1주 차에서 EDA로 확인하지 못한 정보들을 조금 더 찾아보겠습니다. job과 관련하여 수치형 변수 중 salary 변수와의 관계만 살펴보았습니다. 요약 통계량에서 response 별로 차이가 있었던 balance, duration, pdays 변수들과 범주형 변수와의 관계도 살펴보겠습니다.

먼저 3개의 수치형 변수 모두 직업별로 많은 이상치를 가지는 것을 알 수 있습니다. 몇몇 직업의 balance(고객 잔고)가 음의 값을 가지는 것이 보이고, pdays(client가 연락하고 지난 일 수)는 student만 조금 차이가 나고 다른 수준들에서는 모두 이상치를 가지며 비슷한 것이 보입니다. duration 변수에서는 범주별로 IQR이 조금씩 차이가 나는 것을 확인할 수 있습니다.
eligible(상담 자격 유무) 변수를 확인해 보겠습니다.

상담 자격에 관계없이 response의 수준이 모두 존재합니다. 그러나 상담 자격이 없는 경우에 0과 1이 2:1의 비율로 eligible이 'Y'일 때보다 더 많은 비율로 존재하는 것이 보입니다. 'N'의 관측치가 적어서 그럴 수도 있으나 주어진 데이터로만 파악해 본다면 상담 자격이 없는 고객도 제품을 구매하는 고객이 있다는 점을 시사한다고 생각합니다.
housing & targeted를 보겠습니다.

housing(집 소유 여부)과 targeted(타겟팅 대상 유무)는 각 변수의 수준 내에서 결과 변수의 수준이 비슷한 비율로 존재하고 있습니다.
월별 response를 보겠습니다.

month가 어떤 월을 의미하는지는 알 수 없으나 3월, 9월, 10월, 12월에는 제품을 구매한 고객이 더 많거나 구매한 고객과 구매하지 않은 고객이 1:1 정도의 비율을 보이는 것을 알 수 있습니다.
loan과 default를 확인해보겠습니다.

default와 loan은 매우 중요한 변수라 생각합니다. default(기본 목록 존재 유무)가 'yes'인 고객은 제품 구매를 아예 하지 않은 것을 알 수 있습니다. loan(이전 대출 여부)이 'yes'인 고객들도 제품을 구매한 비율이 매우 적은 것을 알 수 있습니다. 따라서 기본 목록이 존재 (default가 yes)하고 loan (이전 대출 여부)이 yes인 고객들은 재품을 거의 구매하지 않는다고 생각할 수 있겠습니다.
지금까지 중요하다 나온 범주형 변수들을 결합하여 새로운 변수를 생성하겠습니다. default+loan, default+eligible, eligible+loan을 생성하겠습니다. 새로운 변수 생성은 [Add Function Columns] 함수를 사용합니다.

<제품의 정보와 데이터의 특징 종합>
해당 제품은 나이와는 큰 관련이 없어 보입니다. 직업별로 제품을 구매한 사람들이 모두 존재하고, 학생까지 제품을 구매했다고 나온 것을 보면 직장인 만을 위한 제품은 아닌 것으로 생각됩니다. 또한 직업에 따른 연봉을 그래프를 직업별 response 비율과 함께 고려해보면 직업+연봉과 response가 밀접한 관련은 없는 것 같다고 보입니다. 교육 수준, 결혼 유무와도 response가 밀접한 관련은 없어 보입니다. 고객 잔고가 심한 음의 값을 갖는 고객 들은 7개 정도의 직업에 분포하며 이들은 대부분 제품을 구매하지 않은 것이 확인 가능합니다. 추가적으로 상담 자격이 있든 없든 제품을 구매하는 데에는 문제가 없으며 집 소유 여부와 타겟팅 대상 유무 또한 마찬가지로 영향이 없음을 알 수 있습니다. 마지막으로 기본 목록이 존재한 고객들은 제품을 구매하지 않고, 이전의 대출 여부가 있는 고객들 또한 제품을 거의 구매하지 않았습니다.
종합해보면 response에서 말하는 제품은 1년 중에서 제품을 구매(가입)할 수 있는 시기가 딱히 정해져 있지 않으며 기본 목록이 존재한다면 제품을 구매할 필요가 없거나 구매할 수 없는 제품일 것이라 추측됩니다. 또한 이전 대출 여부가 있고 없음에 따라서 구매가 가능할 수도 있고 없을 수도 있으며 구매할 이유가 없을 수도 있을 것입니다. 추가적인 정보를 위해 loan과 age 그리고 loan과 targeted와의 관계를 알아볼 필요가 있고, 필자의 생각에 직장에 관계없이 학생도 가입이 가능하기에 주택 청약과 관련된 제품이지 않을까 싶습니다.
2. 변수 간의 상관관계 확인
[Correlation] 함수를 사용하여 변수들 간의 상관관계를 확인할 수 있습니다.

위 3개의 변수 말고도 다른 변수들 모두 상관관계를 확인해 보았으나 절댓값이 0.2 이상인 상관관계를 가지는 변수 쌍을 찾을 수 없었습니다.
3. 이상치 확인
[Outlier Detection]을 사용하여 이상치를 확인할 수 있습니다. 연속형 변수들 중에서 중요하다 생각하는 변수들의 이상치를 확인하고 제거해 보았습니다.

이상치 제거를 하게 되면 너무 많은 관측치를 삭제해야 함을 알 수 있습니다. 위 그래프는 4개의 변수의 이상치를 모두 제거한 그래프입니다. 이후 그래프를 통해서 연속형 변수들 중에서 의미 있는 수치형 변수들을 하나씩 사용하여 이상치를 확인한다고 하더라도 적지 않은 데이터를 삭제해야 하는 것을 확인했습니다.
데이터 손실은 분석에 있어서 좋지 않고 통계량을 보았을 때, 비정상적인 데이터라 생각하지 않기에 이상치에 따른 데이터 삭제를 하지 않고 분석을 진행하기로 하였습니다.
4. 범주형 변수 인코딩
먼저 원핫인코딩을 보여드리겠습니다.
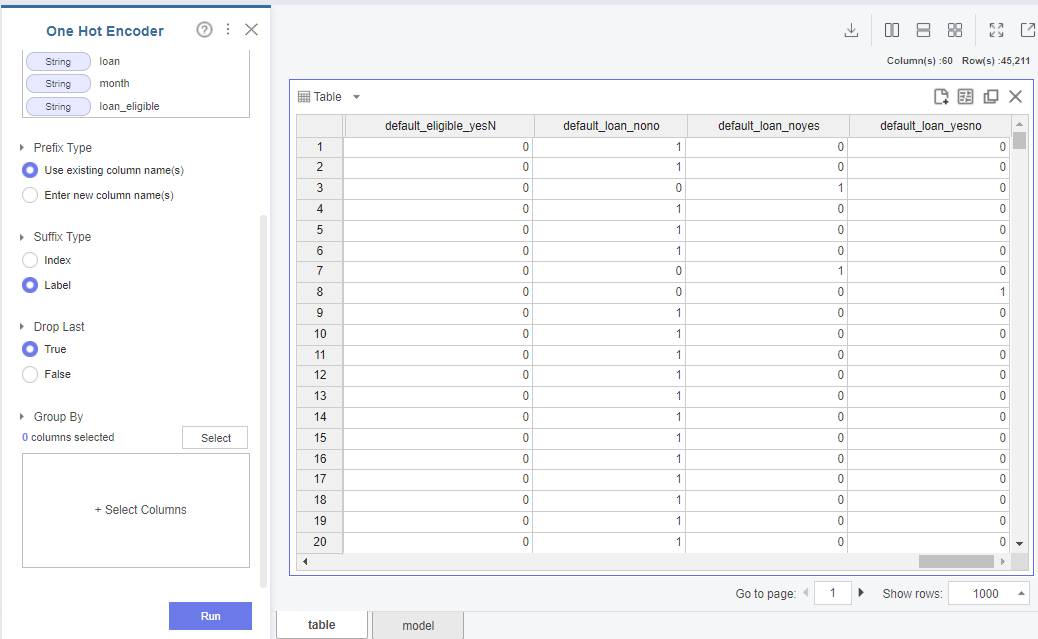
먼저 기본적인 원핫인코딩 후에 라벨 인코딩을 시도해 보겠습니다. 브라이틱스의 원핫인코딩은 [One Hot Encoder] 함수를 사용합니다. 함수의 옵션을 보면 'Suffix Type'이 보이실 겁니다. 'Suffix Type'은 가변수화를 했을 시에 생성되는 변수 이름을 index 형식으로 0,1 등을 사용할 것인지 아니면 변수 수준의 이름(Label)을 사용할 것인지를 묻는 것입니다.
또한 Drop Last는 가변수화를 할 시에 변수 하나를 제거할 건지를 묻는 것입니다. KNN과 같은 알고리즘이 아닌 경우, 일반적으로 수준수-1의 가변수를 생성합니다. 따라서 'Drop Last'를 True로 하였습니다. 이후 알고리즘을 돌리기 전에 기존의 변수들은 모두 제거해 주어야 합니다.
다음은 Label Encoding 입니다. Label Encoding은 [Label Encoder] 함수를 사용하여 인코딩을 진행합니다.

두 개의 수준을 가진 범주형 변수의 경우 Label Encoding과 One Hot Encoding은 같은 결과를 도출합니다. 따라서 3개 이상의 수준을 갖는 범주형 변수들을 선택하였습니다. 'Suffix'는 라벨 인코딩을 진행하여 새로운 변수를 생성할 시에 변수의 이름을 어떻게 할 것인지에 대한 옵션입니다. 현재 '_index'라 되어있기에 새롭게 생긴 변수를 확인해 보면 'job_index'와 같이 '_index'가 모두 붙어있는 것을 확인하실 수 있습니다.
변수들의 특징을 최대한 확인해 보려고 하였습니다. 많은 그래프 중에서 의미 있다고 판단되는 그래프들만 포스팅에 포함했습니다. 미니 프로젝트의 1주 차부터 2주 차까지 시각화 부분만 잘 따라 해 보신다면 어느 정도 그림을 그리는 것에 익숙해지실 것이라 생각합니다! 데이터 전처리에 있어서 아직 모르는 것이 많기에 지금부터는 feature engineering을 위한 다양한 함수들을 알아보려 합니다!
미니 프로젝트 3주 차 포스팅에서는 모델링을 진행할 예정입니다. 알고리즘들을 사용해본 뒤, 성능을 확인하고 데이터 재표현, 범주형 변수의 Label Encoding 등이 성능에 얼마나 영향을 미치는지 확인해 보겠습니다!
감사합니다!
"Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다."
'Brightics 서포터즈' 카테고리의 다른 글
| [팀 미션] 슬기로운 분석생활, 2조 (2) | 2021.07.12 |
|---|---|
| [분석 실습-3주차] Brightics Studio 미니 프로젝트 (2) | 2021.06.28 |
| [분석 실습-1주차] Brightics Studio 미니 프로젝트 (0) | 2021.06.14 |
| [체험] Brightics Studio 다뤄보기 (4) | 2021.06.07 |
| [소개 및 다운로드 방법] 데이터 분석의 길잡이, Brightics AI (0) | 2021.06.06 |



