
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Brigthics Studio
- 분석 툴
- Brightics 서포터즈
- Brightics AI
- 데이터 분석 플랫폼
- 브라이틱스 AI
- michigan university deep learning for computer vision
- Brightics EDA
- 비전공자를 위한 데이터 분석
- 삼성 SDS 서포터즈
- 삼성 SDS
- Random Forest
- 브라이틱스 스태킹
- pymysql
- paper review
- 파이썬 SQL 연동
- 서포터즈 촬영
- Deep Learning for Computer Vision
- 브라이틱스 서포터즈
- 데이터 분석
- 파이썬 내장 그래프
- Python
- 브라이틱스 분석
- Brightics studio
- 머신러닝
- 브라이틱스 프로젝트
- 범주형 변수 처리
- Activation Function
- 딥러닝
- 검증 평가 지표
- Today
- Total
하마가 분석하마
[분석 실습-1주차] Brightics Studio 미니 프로젝트 본문
안녕하세요.
Brightics 서포터즈 노승찬입니다.
앞의 두 포스팅을 통해 Brightics Studio가 무엇인지, 다운로드 방법, 데이터 불러오는 법, 간단한 시각화 등을 소개해 드렸습니다. 이번에는 3주에 걸친 미니 프로젝트를 진행할 예정입니다. kaggle에 있는 데이터를 가져와서 사용하였으며 데이터 링크도 함께 올려드릴게요!
이번 포스팅을 Brightics Studio를 활용한 미니 프로젝트입니다.
[프로젝트 목표]
이번 프로젝트는 은행이 상품 판매 기회를 극대화하기 위해 대상 고객을 선택하는 방법을 찾기 위한 것입니다. 은행의 제품을 고객이 구매할지 여부를 예측하는 분류 모델을 구축하는 것이지요! 미니 프로젝트 1주 차는 데이터 확인 및 이해, 그리고 EDA로 이루어집니다.
1. 데이터 이해
이전 포스팅에서 데이터 불러오는 방법에 대해서 알려드렸습니다. 올려드린 kaggle 링크를 통하여 데이터를 다운로드하신 후, Brightics Studio에 데이터를 불러와 주세요.
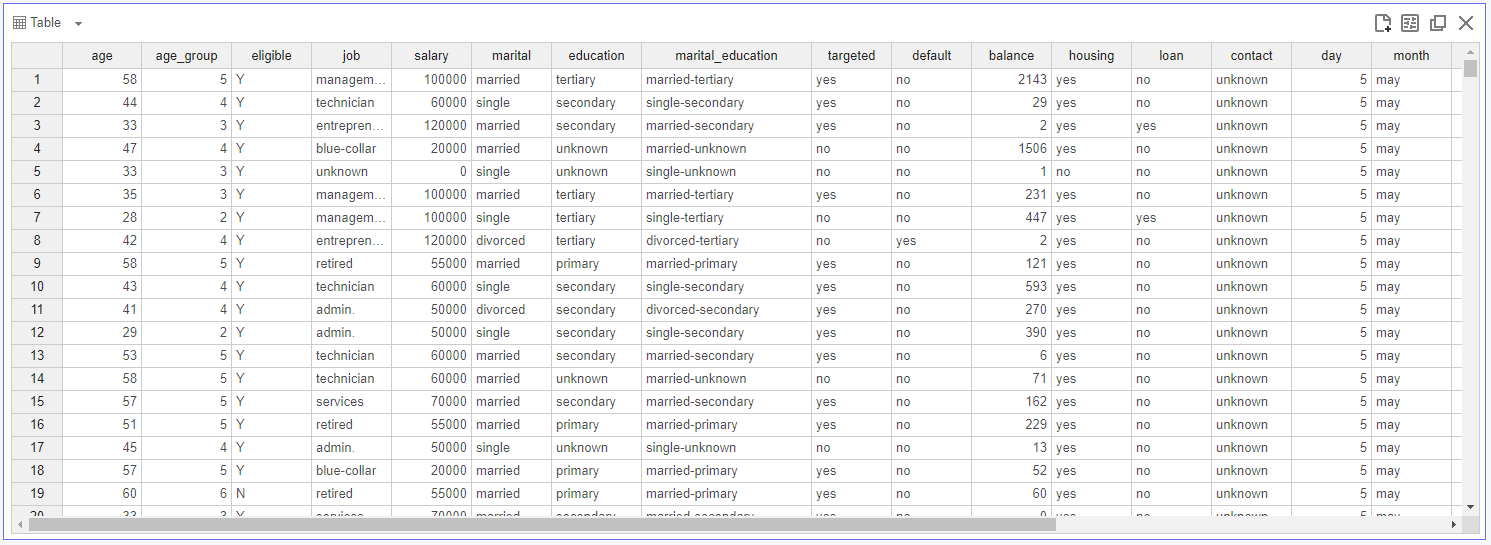
변수 별 의미를 확인하면 다음과 같습니다. 변수에 대한 설명이 정확하게 나와있지 않은 변수는 포함하지 않았습니다.
| 변수명 | 설명 | 변수명 | 설명 |
| age | 나이 | eligible | 상담 자격 유무 |
| job | 직업 | salary | 연봉 |
| marital | 결혼 유무 | education | 교육 수준 |
| targeted | 타겟팅 대상 유무 | default | 기본 목록 존재 유무 |
| balance | 고객 잔고 | housing | 집 소유 여부 |
| loan | 이전 대출 여부 | day | 일 |
| month | 월 | duration | 카드 만들고 지난 일 수 |
| pdays | client가 연락하고 지난 일 수 | response | (결과변수) 구매 여부 |
데이터는 총 23개의 변수로 이루어져 있습니다. 보다 원활한 분석과 해석을 위해서 변수의 의미를 알 수 없는 변수들은 분석에서 제외하려고 합니다. 또한 결과변수가 'y'. 'response'로 두 개가 들어있어 하나를 제외했습니다. 따라서 변수는 총 17개로 선정하고 분석을 진행하겠습니다.
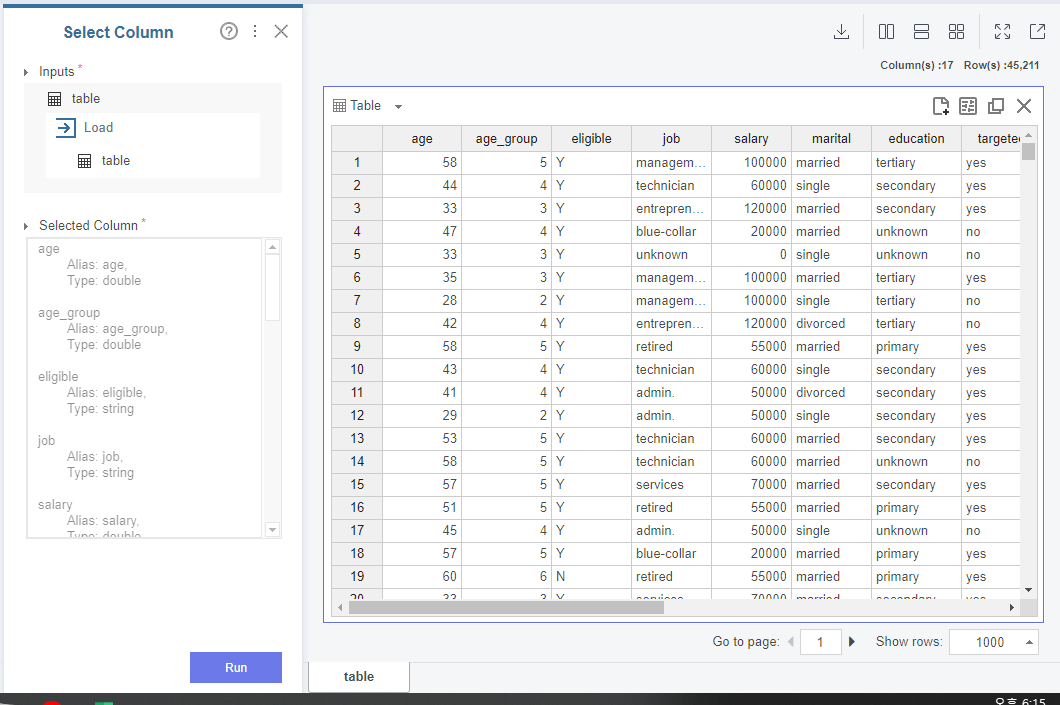
2. 통계량 확인
17개의 변수를 선택한 뒤 통계량을 확인해 보겠습니다. 개별 변수들의 분포와 결측값 유무, 기본적인 통계량 등을 알 수 있습니다. [Profile Table]을 사용하여 변수들을 나타내 보겠습니다.

보다 면밀하게 변수들의 통계량을 살펴보겠습니다. 수치형 변수들의 통계량을 먼저 볼 것이기에 [Statitic Summary]를 사용합니다. 결과변수 'response'에 따라서 수치형 변수들의 차이가 존재하는지 확인하기 위해 Group by를 사용했습니다.

최댓값, 최솟값, 평균, 중앙값, 표준편차를 확인했습니다. age와 age_group 변수를 보면 '제품 구매 여부'에 따른 나이 차이는 거의 없으며, day(발급일) 또한 차이가 없습니다. 결과변수에 따른 차이가 존재하는 수치형 변수는 {balance(고객 잔고), duration(카드 만들고 지난 일 수), pdays(client가 연락하고 지난 일 수)}가 있습니다. 연봉의 경우 유의미한 차이가 있다고 보기는 어렵다 생각합니다.
통계량 해석 및 그래프 해석에 있어서 주관이 개입된 경우가 대부분입니다! 앞의 데이터 이해 및 해석을 바탕으로 하는 feature engineering이 정답이 아니니 데이터와 브라이틱스 스튜디오를 사용하여 분석을 하실 때, 원하는 데로 하시면 될 것 같습니다.
다음은 문자열 통계량을 보겠습니다. 문자열 통계량은 [String Summary]를 사용하여 볼 수 있습니다.

table이 전부 다 보이지 않고 잘렸습니다. 뒷부분까지 확인을 한 다음 파악할 수 있는 점은 범주형 변수에 있어서 결과변수의 차이를 크게 확인하기 어렵다는 것입니다. 최대, 최소, 최빈값만을 봤기에 그럴 수 있으나 통계량만을 보고 판단하면 이후 EDA를 할 때, 2차원 이상의 그래프가 필요하다는 것입니다. 또한 결과변수 'response'에 대해서 불균형이 심한 것을 확인할 수 있습니다.
3. EDA
다음은 EDA를 해보겠습니다. 너무 많은 그림을 넣는 것은 의미가 없다 생각하여 시각화를 하면서 유의미하다고 생각하는 그림이나 도메인을 바탕으로 분석을 할 때, 의미가 있다고 생각되는 변수들에 대한 시각화만 포스팅에 포함하도록 하겠습니다.
먼저 age에 대한 상자 그림입니다.

수치형 통계량에서 확인했듯이 큰 차이가 없다는 것을 알 수 있습니다. 다음 salary와 결과변수와의 그래프를 그려보겠습니다.

IQR에서 차이가 나는 것을 알 수 있습니다.
이제 통계량에서 차이가 났던 변수들을 살펴보겠습니다. 먼저 balance입니다.

다음은 duration 관련 그래프입니다.

다음은 pdays입니다.

위 3개의 변수 모두 각 response에서 극단적인 이상치를 가지는 것이 보입니다. IQR을 조정해보면 조금 더 명확하게 알 수 있음을 확인하고, 우선은 balance, duration, pdays는 response에 따라 조금씩 차이가 있다 생각합니다.
다음은 범주형 변수를 살펴보겠습니다. 추후 트리 계열 알고리즘을 사용할 예정이기에 순서가 있다고 판단되거나 순서가 없어도 연속형 변수와의 관계를 통해서 순서를 발견할 수 있는 변수들은 Label Encoding을 해주려고 합니다. feature engineering은 다음 포스팅에서 다룰 것이기에 이와 같은 분석 방향성만을 염두에 두고 EDA를 계속해서 진행해 보겠습니다.

직업과 연봉 간의 그래프도 필요하다 생각하여 그려보겠습니다.

직업별로 연봉의 차이가 큰 것을 알 수 있습니다. 연봉에 따라서 직업 변수의 수준에 순서를 부여할 수 있는 가능성을 찾았습니다.

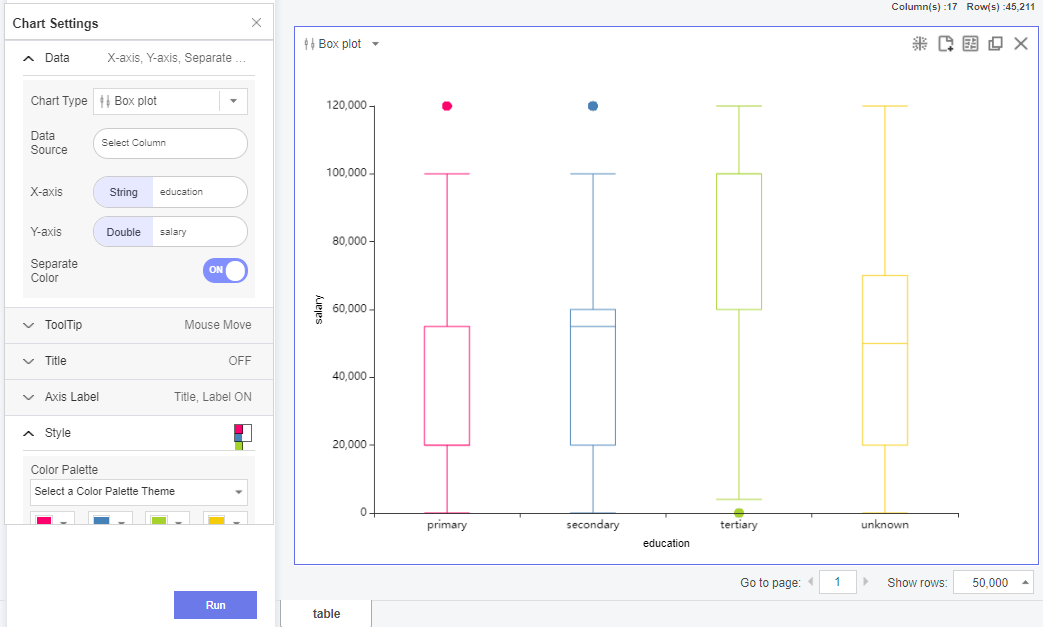
교육 수준 또한 가장 교육을 많이 받은 사람으로부터 아닌 사람까지 단계를 나눌 수 있고, 위와 같이 연봉 또한 차이가 나기에 Label Encoding으로 처리가 가능합니다.

수준별 관측치 수에 차이가 있는 marital 변수를 보면 각 수준별로 response의 0과 1의 비율이 비슷하게 들어가 있다는 것을 알 수 있습니다.

연봉과도 큰 관련은 없어 보입니다.
은행의 어떤 제품인지에 관한 정보가 없으므로 연봉이 중요한지 아니면 직장이 중요한지 등 도메인에 대한 적용이 어렵다고 느낍니다. 다만 돈과 관련되어 있다는 생각 속에서 salary와 최대한으로 관련지어가며 범주형 변수들을 살폈습니다. 다음 포스팅에는 다른 변수들을 더 살펴보고, 지금까지 얻은 정보들을 바탕으로 feature engineering을 진행해 보도록 하겠습니다.
지금까지 [삼성 SDS] 브라이틱스 서포터즈 노승찬이었습니다.
감사합니다!
https://www.kaggle.com/dhirajnirne/bank-marketing
Bank Marketing
Bank marketing Dataset
www.kaggle.com
# 데이터 관련 링크
"Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다."
'Brightics 서포터즈' 카테고리의 다른 글
| [팀 미션] 슬기로운 분석생활, 2조 (2) | 2021.07.12 |
|---|---|
| [분석 실습-3주차] Brightics Studio 미니 프로젝트 (2) | 2021.06.28 |
| [분석 실습-2주차] Brightics Studio 미니 프로젝트 (0) | 2021.06.20 |
| [체험] Brightics Studio 다뤄보기 (4) | 2021.06.07 |
| [소개 및 다운로드 방법] 데이터 분석의 길잡이, Brightics AI (0) | 2021.06.06 |



