
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 서포터즈 촬영
- 머신러닝
- 검증 평가 지표
- Brigthics Studio
- Brightics EDA
- 브라이틱스 AI
- 딥러닝
- 브라이틱스 분석
- Brightics AI
- paper review
- pymysql
- Random Forest
- 데이터 분석
- 데이터 분석 플랫폼
- Brightics studio
- Deep Learning for Computer Vision
- Brightics 서포터즈
- 삼성 SDS 서포터즈
- 브라이틱스 서포터즈
- 삼성 SDS
- Activation Function
- 분석 툴
- michigan university deep learning for computer vision
- 범주형 변수 처리
- 브라이틱스 프로젝트
- 브라이틱스 스태킹
- Python
- 파이썬 SQL 연동
- 비전공자를 위한 데이터 분석
- 파이썬 내장 그래프
- Today
- Total
하마가 분석하마
19~20. Generative Models 1,2 본문
19~20. Generative Models 1,2
Rrohchan 2022. 2. 28. 12:59Michigan University의 'Deep Learning for Computer Vision' 강의를 듣고 정리한 내용입니다.
Generative Models 1,2
Supervised vs Unsupervised Learning

1. 지도학습
- Classification : image가 입력되면 class를 출력
- Regression : 수치 예측
- Object Detection : image 객체들의 bounding box를 그림
- Semantic segmentation : 모든 pixel마다 각 pixel이 속하는 category 결정
- Image captioning : image에 대해 자연어의 형태를 띈 문장을 출력
2. 비지도학습
- Clustering : 유사한 데이터들끼리 그룹화
- Dimensionality reduction : data가 가장 많이 퍼져있는 축을 찾아냄 (PCA)
- Autoencoder : 입력 data에 대해 재구성 (추가적인 label 없이도 feature representation을 학습시킬 수 있음)
- Density estimation : 데이터가 가진 기본적인 분포 추정
Generative model vs Discriminative model

| Generative model | Discriminative model |
| Data를 생성하기 위한 model (비슷한 분포를 가지는 new_data 생성 |
Data를 구별하기 위한 model. 데이터가 주어졌을 때 특정 클래스에 속할 확률을 다룸 |
| classifier 같은 경우 바로 활용 불가 bayes를 이용하여 likelihood 나 posterior로 변경하여 구함 |
classifier에 바로 활용 가능 |
| data가 어떻게 생성되었을지 학습을 한 후classification 진행 | 모델이 어떻게 생성되었는지에는 관심 없음 |
| p(x,y)= p(y|x)*p(x) => 추가적인 p(x)가 필요 p(x)가 잘못 모델링 되면 성능 저하 |
p(x)가 필요없음 |
| 개와 고양이를 분류할 때, 각각에 대해서 학습을 한 이후 분류를 진행 | 개와 고양이를 분류할 때, data는 보지 않고 각 class를 잘 분류하도록 학습됨 |
Generative models

먼저 Explicit density에 대해서 알아보겠다.
p(x)가 어떤 분포를 띄는지 정의하고 이를 찾는데 초점을 둔다. Explicit density model은 training data의 likelihood를 높이는 방향으로 학습을 진행한다. (까지가 각 pixel이 등장할 확률이라면, 해당 pixel들로 구성된 이미지가 나타날 확률은 각 pixel들의 확률곱입니다. 따라서 아래와 같은 식으로 나타낼 수 있다.
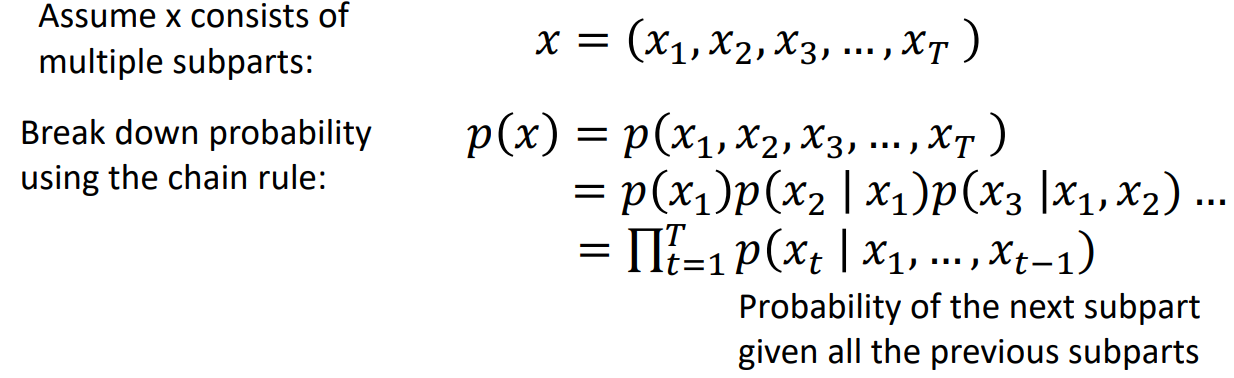
이러한 explicit 방식은 데이터가 더 복잡해질수록 분포를 식으로 표현해서 계산하기 어렵기 때문에 implicit model 쪽을 많이 선택한다. 대표적인 implicit model로는 GAN이 있다.
Implicit density의 경우 p(x)가 어떤 분포를 띄는지 정의하는 데는 관심이 없고, 오로지 data를 생성하기를 원한다.
Autoencoders

Autoencoder를 transfer learning하여 사용하는 부분은 다음에 알아보도록 하겠다.
- Sparse autoencoder
- Denoising autoencoder
Variational Autoencoders
Autoencoder는 encoder의 학습을 위해 decoder를 만들었다. (encoder로 차원을 축소) 그러나 Variational Autoencoder는 decoder로 새로운 데이터를 생성하기 위해서 개발되었다.

VAE는 다음과 같은 형태를 가지고 있다. explicit model이기에 data의 분포를 사용한다.

Vanilla AE와 다르게 input 값이 바로 z로 되지 않는다. input data로 부터 평균과 표준편차를 먼저 출력하고, 이후 그 모수를 사용, reparameterization을 사용해서 latent variable z를 만들어낸다. 이 과정에서 z가 normal distribution을 따른다고 가정한다. KLD를 사용해서 encoder를 통과하는 확률분포가 normal distribution을 따르도록 최적화시킨다.

위 그림은 Decoder만 나타낸 것이다. p(x|z)는 latent variable z가 주어졌을 때, x의 확률분포를 의미한다. p(z)는 latent variable의 확률 분포를 의미한다. (우리가 나타내고자 하는 x를 generate하기 위한 z)


다음은 Encoder의 도움을 받아 학습을 하는 부분이다.


'Deep learning > Michigan university deep learning' 카테고리의 다른 글
| 13. Attention (0) | 2022.02.20 |
|---|---|
| 12. Recurrent Neural Networks (0) | 2022.02.11 |
| 11. Training Neural Network 2 (0) | 2022.02.10 |
| 10. Training Neural Network (0) | 2022.02.07 |
| 8. CNN Architectures (0) | 2022.02.07 |



