
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 분석 플랫폼
- 브라이틱스 분석
- Activation Function
- 브라이틱스 스태킹
- paper review
- Brightics studio
- Brightics 서포터즈
- Brightics AI
- 브라이틱스 서포터즈
- 머신러닝
- 삼성 SDS
- 서포터즈 촬영
- 범주형 변수 처리
- 브라이틱스 AI
- Brightics EDA
- 검증 평가 지표
- Random Forest
- 삼성 SDS 서포터즈
- 데이터 분석
- 파이썬 SQL 연동
- 브라이틱스 프로젝트
- Python
- michigan university deep learning for computer vision
- Brigthics Studio
- 딥러닝
- 파이썬 내장 그래프
- 비전공자를 위한 데이터 분석
- Deep Learning for Computer Vision
- pymysql
- 분석 툴
- Today
- Total
하마가 분석하마
12. Recurrent Neural Networks 본문
12. Recurrent Neural Networks
Rrohchan 2022. 2. 11. 13:31Michigan University의 'Deep Learning for Computer Vision' 강의를 듣고 정리한 내용입니다.
Recurrent Neural Networks
Classical Approach for Time Series Analysis
- Time domain analysis -> width, step, height of signal
- Frequency domain analysis -> Fourier analysis or wavelets
- Nearest neighbors analysis -> Dynamic time warping (DTW)
- Probabilistic Model -> Language modeling
- (S)AR(I)MA(X) models -> Autocorrelation inside of time series
- Decomposition -> Time series = trend part + seasonal part + residuals
- Nonlinear Dynamics -> Differential Equation (ordinary, partial, stochastic, etc..)
- Machine Learning -> Use ML model with hand-made features
MLP : Stack of fully connected layers
임의적인 길이를 가지고 있는 sequence 데이터에는 부적절하다. 고정도니 길이의 sequence만 사용한다고 하더라도 parameter가 매우 많아지기에 부적절하다.
CNN : Stack of Conv+pooling+fully connected layers
1d convolution은 time series analysis에 사용된다.
RNN Process Sequences

- one to one : 앞에서 배웠던 CNN이나 Fully-Connected NN은 input이 1개, output이 1개인 형태였다. 예를 들어, 이미지 한장이 input 되면, 어떠한 모델 아키텍처를 거쳐서 이미지에 대한 label(개 / 고양이 등)을 output으로 반환한다.
- one to many : Sequence의 개념을 갖고있는 것이 input으로 들어가거나, output으로 출력될 수 있다. one to many문제의 예시로, 이미지를 입력하면, 어떠한 연산을 거쳐서 문장(연속적인 단어들)을 출력한다. 이때 문장 자체를 코딩하는 방법이 아니고, 단어를 쪼개서 코딩때문에 sequence of words로 볼 수 있는 것이다.
- many to one : 동영상 즉, 연속적인 프레임(이미지)을 입력하면, 어떠한 연산을 거쳐서 label(class)를 출력한다.
- many to many : 기계번역이 있다. 예시로 한국어 문장이 입력되면, 영어 문장이 반환된다. many to many 문제에서는 input이 들어오자마자 output이 나오는 것도 있다. 따라서 input은 sequence of images, output은 sequence of labels가 될 것이다.
RNN
현재 step의 ouptut과 이전 step의 output을 같이 고려해서 현재 step의 output을 만드는 것. 같은 트렌드가 반복적, 재귀적(Recurrent)으로 적용된다는 것이다. 따라서 RNN은 재귀신경망, 순환신경망으로도 불린다.

이전 시점의 output인 ht-1 (hidden state)에 weight_hh를 곱해주어 (processing 하여) 현재 step에 맞게 한다.
모든 timestep에 대해서 같은 parameter와 같은 함수가 적용된다. (RNN에서는 pararmeter가 sharing 된다.)
위 그림의 파란색 평행사변형 (weight_hh)과 초록색 사다리꼴 (weight_xh)들의 parameter는 모두 같다.

여기서 fw는 가중치를 old hidden state와 input vector에 각각 곱해주고 활성화 함수를 씌우는 함수를 의미한다. (weight_hh와 weight_xh는 서로 다르다.) 위 과정을 풀어서 써보면 아래와 같다.

현재 step의 hidden state는 fw(ht-1, xt)로 구하는 데 활성화 함수로는 tanh()를 사용한다.
RNN Computational Graph




각 시점에서의 loss들 전체를 다 평균 내서 train 할 대상의 final loss를 만든다.

더 자세한 예시를 보겠다. 밑의 그림은 'hell'을 입력하면 'ello'를 출력해주는 모델이다. 검은색으로 라인이 그려진 것은 2번 경로로 backprop이 이루어지는 것을 나타낸다. 보라색 선이 업데이트되는 가중치들의 선을 의미한다.

아래는 3번 경로로 backprop이 되는 것을 보여준다.

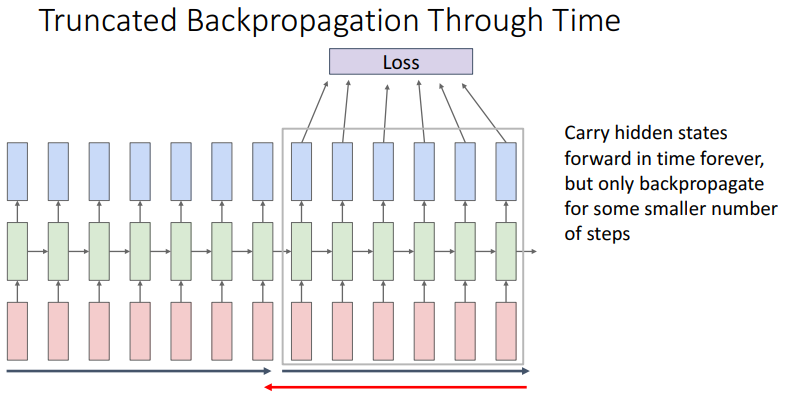
Long Sequence 처리
상당히 긴 sequence가 input 되었다고 보면 forward pass 연산은 가능해도 backward pass 할 때 메모리의 문제가 크다. W에 대한 그래디언트 계산을 위해서는 수많은 computational graph가 모두 살아있어야 하며, 수많은 경로가 존재하기 때문이다.

메모리 로드를 막기 위한 practical 한 방법으로는 sequences를 잘라내서 진행하는 방법이 있다. 예를 들어 한 문단(chunks of the sequence)에서 자른다. Forward pass와 backward pass를 진행하여 W를 업데이트하고, hT hidden state를 만든다. 앞에서 나온 hT를 가지고 다음 input 벡터들과 함께 hidden state를 만들어고, forward pass, backward pass를 진행한다.
Gradient Problem of the vanilla RNN
Vanilla RNN의 구조에서 W matrix가 모든 시점의 fw(ht−1,xt) 연산에서 활용되고 있음을 확인할 수 있다. 따라서 backward pass과정에서도 W^T가 계속해서 곱해진다, computational graph와 합성함수 미분 과정을 통해 자세히 살펴보겠다.
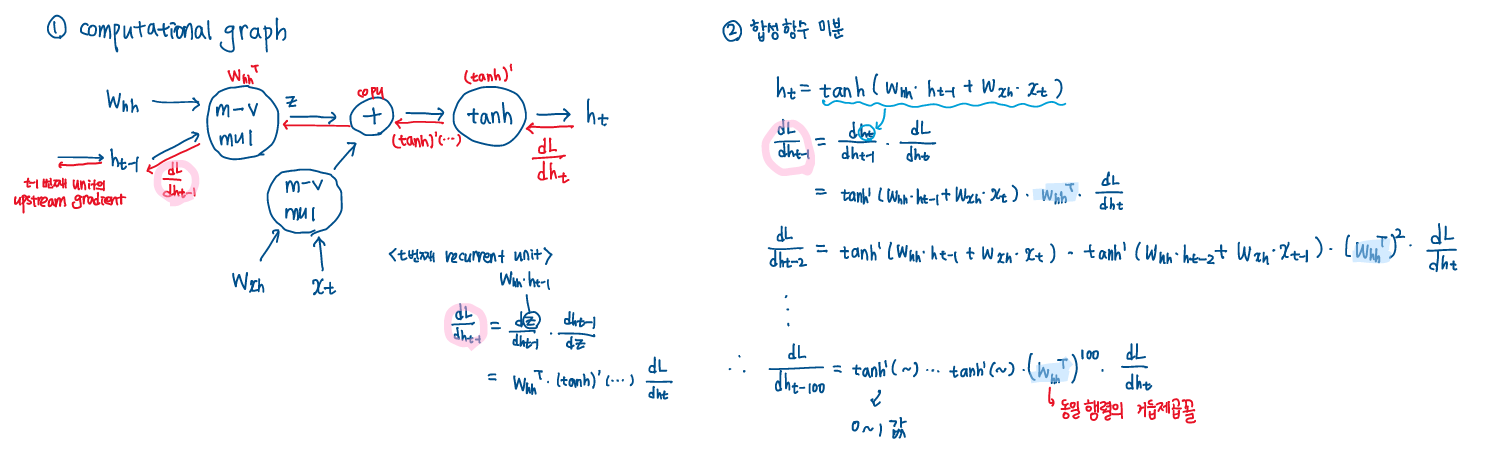
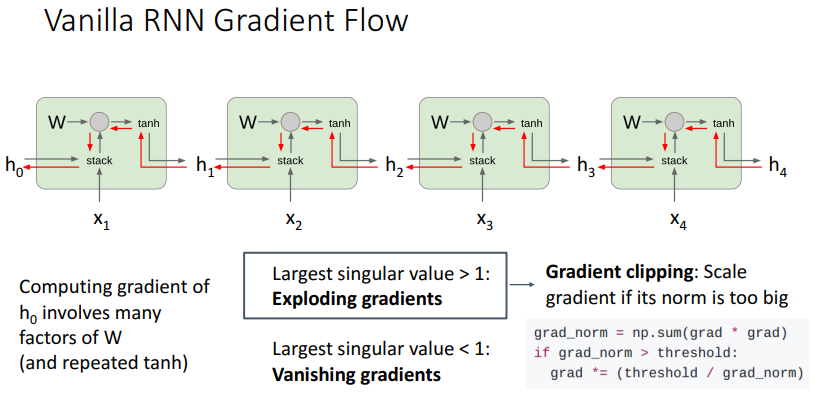
h0의 그래디언트는 old value들의 tanh미분 값들의 곱과 WThh의 거듭제곱의 곱으로 표현된다. Scala값으로 생각해보면, scala값이 1보다 작으면, (0.xx1)^100을 하면 거의 0으로 간다. 반대로 scala값이 1보다 크다면, 거듭제곱을 하면 값이 매우 커진다.
마찬가지로, WThh의 거듭제곱 largest singular value가 1보다 크면, 한 축의 방향으로 계속해서 증가하게 된다. 이는 컴퓨터의 수치적인 문제를 야기한다. Exploding gradients의 문제는 그래디언트 스케일이 설정한 임계값보다 커질때커질 때, 조정하는 gradeint clipping으로 해결할 수 있다.
또한 tanh()의 반복 사용도 vanishing gradient에 영향을 미친다.

tanh 함수의 미분 값은 0~1이다. 역전파가 될 때, tanh()가 많다면 gradient 값이 빠르게 작아진다.
LSTM
vanilla RNN의 그래디언트 소멸 문제를를 해결하기 위해서, Long Short Term Memory(LSTM)가 제안되었다.

기존에는 h라인을 사용해서 이를 output으로 사용하고, 이전 step의 input으로도 사용했다. 따라서 한 채널 h에 2가지 역할이 동시에 부여되니 병목현상이 생긴다. 이러한 역할을 나누기 위해 시간에 따라서 정보를 공급할 수 있는 information flow를 만들어 보았다.
LSTM에서는 vanilla RNN에서 "cell" state가 추가되었다. 이때, cell state는 내부적으로 hidden variable 간의 연산에만 활용한다. loss가 필요하다면 ht("hidden" state)를 활용해서 구한다.

남길건 남기고 잊어버릴 건 잊어버리고, 새로 추가할 건 추가해서 Cell State에 중요한 정보만 계속 흘러가도록 설정
Hidden State는 cell state를 적당히 가공해서 내보낸다. cell state에는 이전의 정보와 현재의 정보가 같이 들어있다. 이 중에서 현재 state에서 내보낼 정보만 선택해서 내보낸다.
Gate
정보의 중요도를 결정한다.
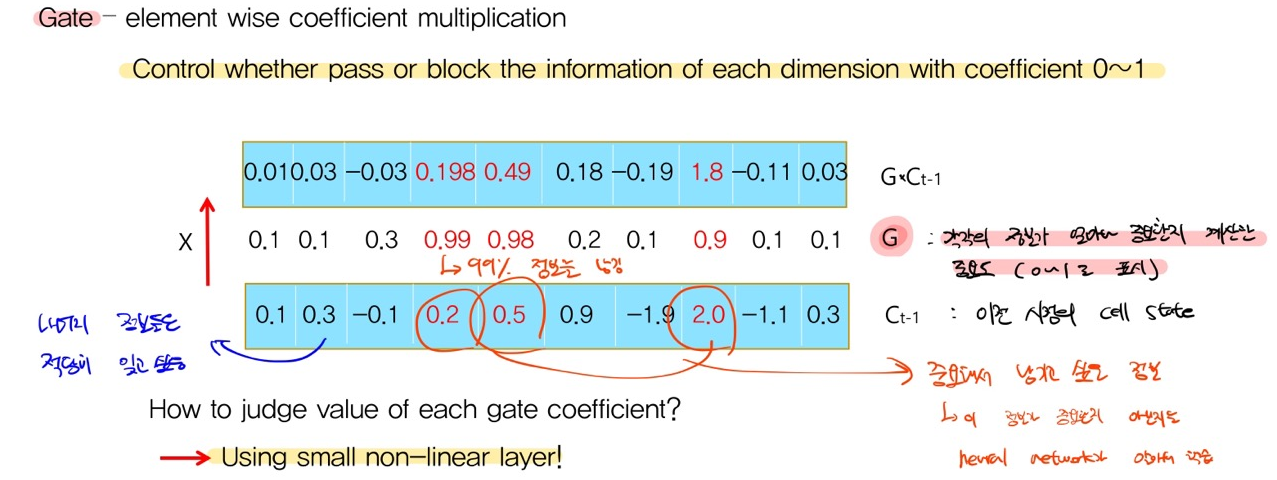

LSTM 순서
- Ct-1 에서 불필요한 정보를 지운다.
- Ct-1에 새로운 인풋 xt와 ht-1를 보고 중요한 정보를 넣는다.
- 위 과정을 통해 Ct를 만든다.
- Ct를 적절히 가공해 해당 t에서의 ht를 만든다.
- Ct와 ht를 다음 스텝 t+1로 전달한다.







'Deep learning > Michigan university deep learning' 카테고리의 다른 글
| 19~20. Generative Models 1,2 (0) | 2022.02.28 |
|---|---|
| 13. Attention (0) | 2022.02.20 |
| 11. Training Neural Network 2 (0) | 2022.02.10 |
| 10. Training Neural Network (0) | 2022.02.07 |
| 8. CNN Architectures (0) | 2022.02.07 |



