
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 범주형 변수 처리
- 데이터 분석
- 브라이틱스 AI
- 브라이틱스 스태킹
- Random Forest
- 데이터 분석 플랫폼
- pymysql
- Brightics AI
- Brightics studio
- Python
- 비전공자를 위한 데이터 분석
- 브라이틱스 프로젝트
- 분석 툴
- Deep Learning for Computer Vision
- Brigthics Studio
- 브라이틱스 서포터즈
- 딥러닝
- paper review
- Brightics 서포터즈
- 삼성 SDS 서포터즈
- 머신러닝
- Activation Function
- michigan university deep learning for computer vision
- Brightics EDA
- 서포터즈 촬영
- 삼성 SDS
- 파이썬 내장 그래프
- 파이썬 SQL 연동
- 브라이틱스 분석
- 검증 평가 지표
- Today
- Total
하마가 분석하마
[개인 분석-5주차] Loan & Bank Feature 본문
안녕하세요.
Brightics 서포터즈 노승찬입니다.
저번 주차에는 공백값을 변수 간의 관계와 도메인 정보를 바탕으로 제거 및 채웠었습니다.
이번 주차에는 은행 데이터이니 만큼 가장 중요할 수 있는 '대출 정보'와 '은행 정보'를 조금 더 면밀하게 살펴보겠습니다.

Loan & Bank Feature
프로젝트 목표
고객의 기본 세부 정보를 바탕으로 잠재 고객을 타겟팅 할 수 있는 알고리즘을 개발하여 보다 나은 리드 전환을 이끌어 내는 것을 목적으로 합니다.
은행 관련 변수 (Customer_Existing_Primary_Bank_Code와 Primary_Bank_Type 확인)
저번 주에 은행 관련 변수들을 사용해서 알고리즘을 돌려보겠다고 했었는데요. 결과변수 개수가 너무 적다는 점과 더불어 EDA에서 놓친 점이 있어 더 자세하게 알아보려 합니다. 은행 관련 정보는 모두 결측값을 새로운 범주로 만든 상태에서 진행했습니다. 또한 중간의 간단한 전처리 들은 너무 많아서 포스팅에 담지 않았습니다.

None 범주 6435명 중에서 15명 만이 '잠재 고객'으로 분류됩니다. 비율로 보아도 은행정보가 None 타입인 (없는) 고객들은 대부분은 '잠재 고객'으로 분류되지 않았습니다. 월급의 경우 큰 차이는 보이지 않고 있습니다.
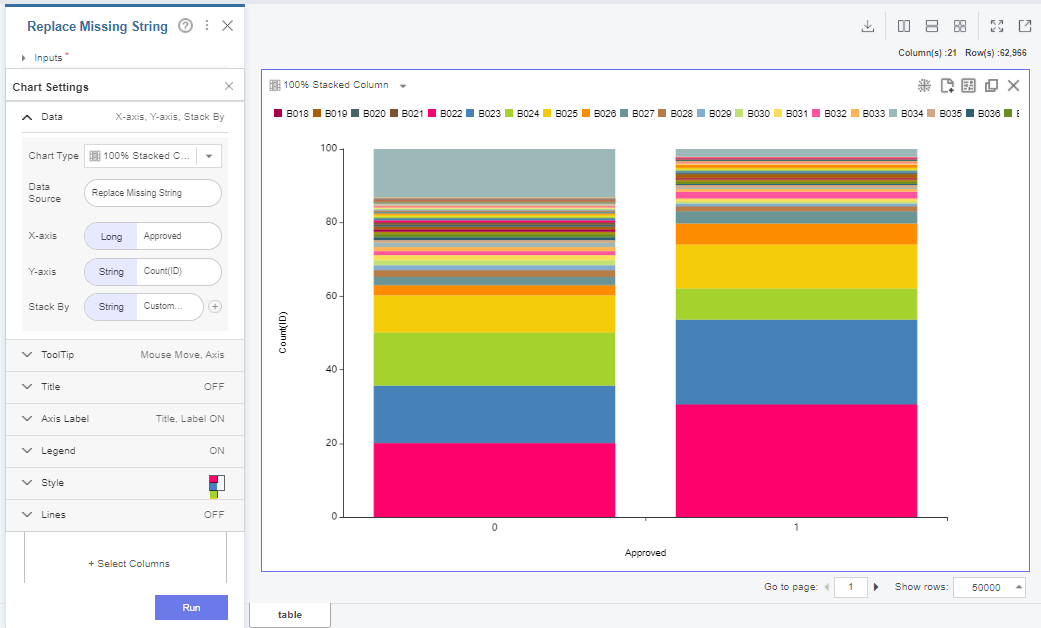
Customer_Existing_Primary_Bank_Code에서는 '잠재 고객'과 그렇지 않은 고객 간에 비율 차이 등은 없었습니다. 현존하는 은행 계좌라고 변수를 해석해보면 계좌 종류의 비율이 조금씩 다르고 맨 위의 쥐색 비율의 차이가 가장 큰 것을 알 수 있었습니다. 추후 트리 계열 알고리즘을 사용한다면 Label encoder를 사용해보면 좋을 것 같습니다.
대출 관련 변수의 영향 확인 (Loan_Amount와 Loan_Period 영향력 확인)
대출 관련한 변수에서 Loan_Amount와 Loan_Period 변수는 모두 동일한 null 값이 존재합니다. 두 변수에 존재하는 27000여개의 null 값을 어떻게 할지 eda와 모델링을 통해 변수의 영향력을 확인해보겠습니다.
먼저 대출 관련 정보가 null로 이루어진 고개들입니다.

대출 정보가 없는 고객들은 24752:160로 이루어져 있고, 나이는 골고루 퍼져 있습니다.

승인한 고객과 승인하지 않은 고객들의 연봉 차이를 보면 둘 모두 이상치가 많이 존재합니다. 또한 평균으로 보면 남성의 연봉이 여성보다 조금 더 높습니다.

대출 정보가 없는 고객들은 성별에서 차이가 크게 드러났습니다. 대부분이 여성고객이고, 남성의 경우 '잠재 고객'이 단 한 명도 없습니다. 다양한 범주를 접목해서 보았을 때, Employer_Category2에서의 차이도 컸습니다. 남성 고객이 적어서 그럴 수도 있으나 1,2,3의 level을 전혀 찾아볼 수 없었습니다.
여기까지만 보더라도 null값의 범주가 성별, employer_category에 따라서 '잠재고객'의 수 차이에 여러모로 구분을
주고 있다고 보입니다.
다음은 null이 없는 고객들입니다.

대출 정보가 있는 고객들은 37321:734이고 없는 고객들은 24752:160으로 이루어져 있습니다. 대출 정보가 존재하지 않는 고객과 마찬가지로 나이는 골고루 퍼져있습니다.
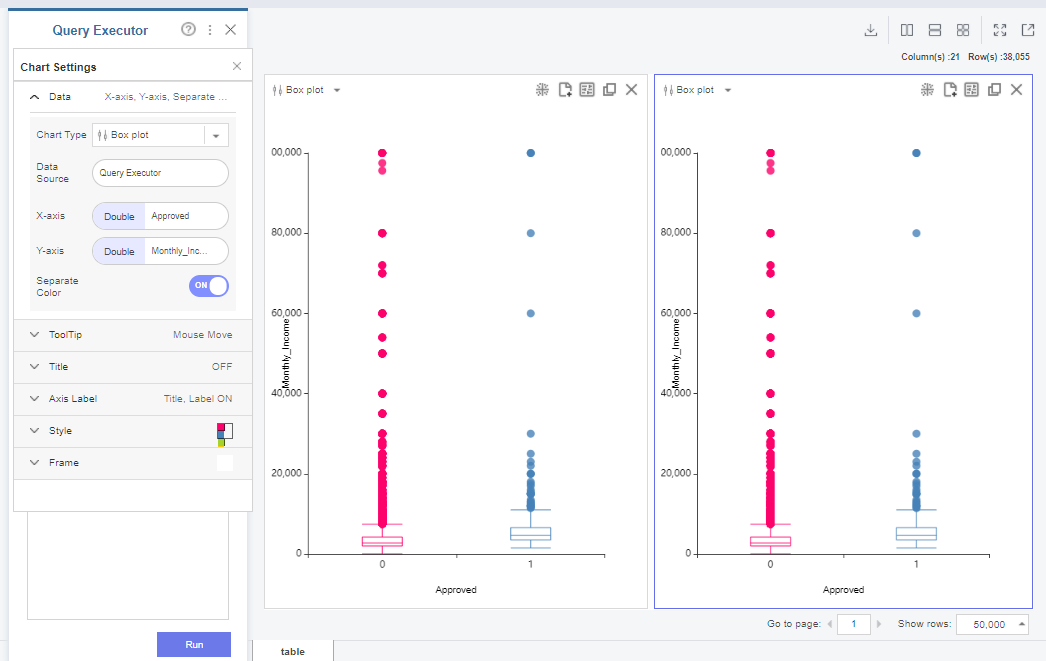
대출 정보가 존재하지 않는 경우, 잠재 고객과 아닌 고객 간의 월급 차이가 유의미하다고 보기는 어렵습니다.

대출 정보가 존재하는 고객도 마찬가지로 성별과 Employer_Category2별로 확인해 보았습니다. Loan_Period가 null인 고객층과 다르게 남성의 고객이 많은 것을 확인할 수 있었습니다. Employer_Category2를 보면 Employer_Category2 null인 여성 고객은 없습니다. 또한 여성과 남성 모두 4level의 Employer_Category2가 많습니다.
Loan_Period가 유의미하면 이 변수의 결측값을 예측해서 사용하려고 했습니다. EDA로 살펴본 바, 예측을 하지 않고 null이라는 결측값을 'None'이라는 새로운 범주로 만들어도 좋은 영향을 보여줄 것 같습니다.
다음 주차부터는 모델링을 해보려고 합니다. 지금까지 했던 전처리를 바탕으로 다양한 모델을 하나씩 적용해보고, 변수들의 영향력을 확인해보도록 하겠습니다. 감사합니다!
"Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다"
<a href='https://kr.freepik.com/vectors/people'>People 벡터는 pch.vector - kr.freepik.com가 제작함</a>
'Brightics 서포터즈' 카테고리의 다른 글
| [개인 분석-7주차] Modeling 2 (0) | 2021.10.19 |
|---|---|
| [개인 분석-6주차] Modeling (0) | 2021.10.05 |
| [개인 분석-4주차] Replace White Space & EDA (0) | 2021.09.22 |
| [개인 분석-3주차] EDA (0) | 2021.09.14 |
| [개인 분석-2주차] 도메인 이해 및 데이터 살펴보기 (0) | 2021.09.07 |



