
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 파이썬 SQL 연동
- 검증 평가 지표
- paper review
- Activation Function
- 비전공자를 위한 데이터 분석
- 브라이틱스 프로젝트
- Brightics 서포터즈
- Random Forest
- 삼성 SDS 서포터즈
- 파이썬 내장 그래프
- michigan university deep learning for computer vision
- 머신러닝
- Deep Learning for Computer Vision
- 브라이틱스 스태킹
- Brigthics Studio
- Brightics studio
- 브라이틱스 분석
- 삼성 SDS
- pymysql
- 분석 툴
- Python
- 브라이틱스 서포터즈
- 서포터즈 촬영
- 데이터 분석 플랫폼
- 딥러닝
- Brightics EDA
- 데이터 분석
- 범주형 변수 처리
- 브라이틱스 AI
- Brightics AI
- Today
- Total
하마가 분석하마
[팀 분석-4주차] 모델링2 본문
안녕하세요.
Brightics 서포터즈 노승찬입니다.
[팀 분석-3주차]에는 모델링을 해보았습니다.
이번 주차에는 임현철 프로님께서 보내주신 스태킹 방법을 적용해보도록 하겠습니다.
모델링2
변수 구성
저희는 2개의 feature set과 각 feature set에 XGBoost, Random Forest를 사용한 후, 스태킹을 진행했었습니다.

스태킹2
개별 알고리즘의 예측 확률 값을 변수로 사용하여 예측하는 것이 아닌 새로운 방식의 스태킹을 시도해 보겠습니다.


위 논문의 기본 개념은 스태킹을 할 때, 각 (알고리즘의 정확도 곱하기) * (class 별 확률)로 보다 자세한 예시를 들면 다음과 같습니다. 이번 프로젝트에 사용한 것으로 예시를 들어보겠습니다.
{RF 알고리즘 정확도*(RF 알고리즘의 credit별 확률) + XGB 알고리즘 정확도*(XGB 알고리즘 credit별 확률)}/(RF 알고리즘 정확도+XGB 알고리즘 정확도)
저희는 feature set을 총 두 개를 사용했기에 위와 같은 방식을 두 번 해주어야 하며 위의 방식을 적용했을 시에 최종적으로 feature set1,2 별 결괏값으로 2개가 나오게 됩니다. 기존에 택했던 방식은 feature set1에서의 결과인 credit 별 확률 값 6개와 feature set2의 결과인 credit 별 확률 값 6개, 총 12를 stacking 하는 것이고, 위 방식은 feature set 별 알고리즘 정확도를 사용하여 합쳐 총 6개의 credit 확률 값이 나오게 됩니다.
먼저 iris 데이터를 사용하여 위 방법을 적용한 예시를 가볍게 보여드리겠습니다.
1. iris 데이터 사용

Load 함수로 iris 데이터를 불러온 후, row number를 추가해준 모습입니다.
2. 모델링

행 번호를 추가한 데이터에 의사결정나무와 나이브 베이즈 알고리즘을 fitting 시키고 predict 한 값을 위와 같이 두 개 뽑아냅니다. (NB Tree 논문의 내용을 브라이틱스로 구현한 코드는 논문의 내용을 보다 직관적으로 보여주기 위해서 정확도를 각 class 별 확률 값에 곱하는 과정과 정확도를 따로 산출하는 작업을 모두 따로 진행한 것 같습니다.)
- predict -> Evaluate Classification : 정확도 산출

2. predict -> join : class 별 확률 값 산출

join 과정에서는 inner join을 하였고 행 번호와 target 값을 기준으로 하여 두 알고리즘의 target class 별 확률 값을 병합하였습니다.

다음은 Evaluate Classification에서 나온 정확도를 쿼리문에 사용하기 위해 [Get Table] 함수를 사용해서 테이블 형태로 만들어 줍니다.
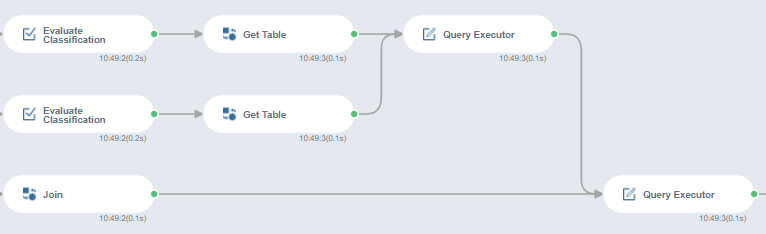

알고리즘 별 class 확률 값들과 각 알고리즘의 정확도를 join 하여 새로운 테이블을 만듭니다. SQL 문을 활용하여 Query Executor를 사용해서 두 개의 테이블 결과를 모두 가져와줍니다.

SQL의 case when을 사용해서 맨 처음 말씀드린 방식을 적용해줍니다.

관측치의 종별 예측값의 최대 확률 값을 구하고, 그 확률 값이 최대로 되는 class로 예측을 수행합니다.
위의 모든 과정들은 직접 해보셔야 이해가 빠르시기에 댓글 남겨주시면 파일 보내드리도록 하겠습니다!
저희 프로젝트에서 해당 과정을 함수를 모두 사용해 보지는 못하였습니다. (SQL 문의 에러를 잡지 못해서요 ㅠㅠ)
대신 같은 함수를 쓰지 않고 다른 함수를 사용하여 위 방식을 적용해보았습니다. feature set이 두 개라서 알고리즘 별 정확도를 병합하는 과정을 어떻게 해야 하는지 고민이 많았는데 고심 끝에 기존의 방식과 접목시키는 방법을 택하였습니다.
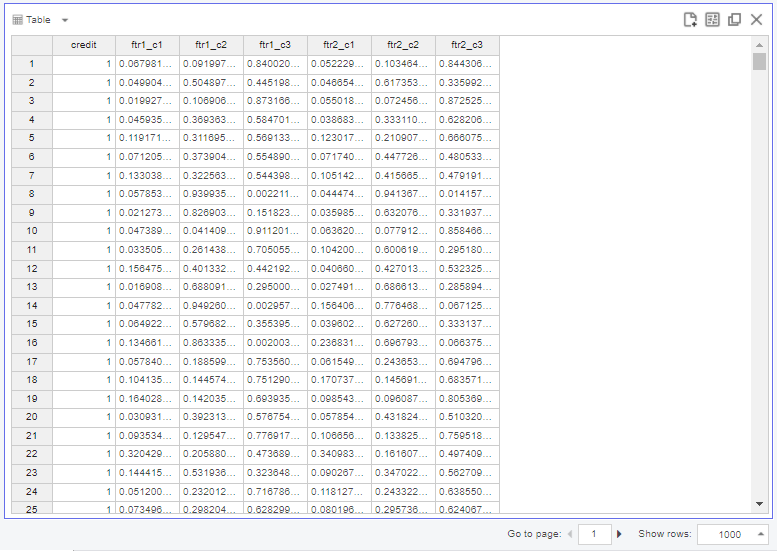
위 테이블이 feature set 별 결과를 NB Tree 방식으로 credit 별 확률 값을 새롭게 계산한 값입니다.


기존의 결괏값 보다 좋은 결과가 나오지는 않았으나 다르게 적용해보면 더 좋은 결과가 나올 수도 있을 거라고 생각합니다. 각 함수에서의 테이블 및 결괏값들을 자유롭게 변형하고 병합하는 것이 익숙하지 않아서 프로젝트 내에서 join과 Get Table 등의 함수를 사용하지 못하였는데요. ㅠㅠ 모두 수작업으로 진행했던 이번 프로젝트와 달리 다음에는 NB Tree 예시와 같이 결괏값을 함수로 따로 저장하여 사용하는 방식으로 진행해보겠습니다!
정리된 브라이틱스 함수 예시를 보고 저희 데이터에 사용하는 것이 매우 어려운 것을 느낄 수 있는 시간이었습니다..
더 다양한 방법과 새로운 시도를 해보며 브라이틱스 함수 사용과 더불어 분석 측면에서도 많은 정보를 드릴 수 있도록 노력하겠습니다, 감사합니다!
"Brightics 서포터즈 활동의 일환으로 작성된 포스팅입니다."
'Brightics 서포터즈' 카테고리의 다른 글
| [개인 분석-2주차] 도메인 이해 및 데이터 살펴보기 (0) | 2021.09.07 |
|---|---|
| [개인 분석-1주차] 분석 주제 선정 (0) | 2021.08.31 |
| [팀 분석-3주차] 모델링 (0) | 2021.08.17 |
| [팀 분석-2주차] 우승자 코드 분석 및 아이디어 도출 (0) | 2021.08.09 |
| [팀 분석-1주차] 프로젝트 소개 및 데이터 이해 (2) | 2021.08.02 |



